
As I have mentioned before, I have been involved in the re-platform of the Inventory system here at Shopzilla for the last 14 months. During this time we got to experiment with a couple of approaches with great success. One was the concept of blackbox testing and whitebox testing using Behaviour Driven Development (BDD). Before I explain what this is, let’s take a look at the new Inventory platform.
Our new Inventory platform switched from a feed batch processing approach to a streaming model. This meant that we had a number of services deployed, each with their own responsibilities in the pipeline. At a high level this is as follows:
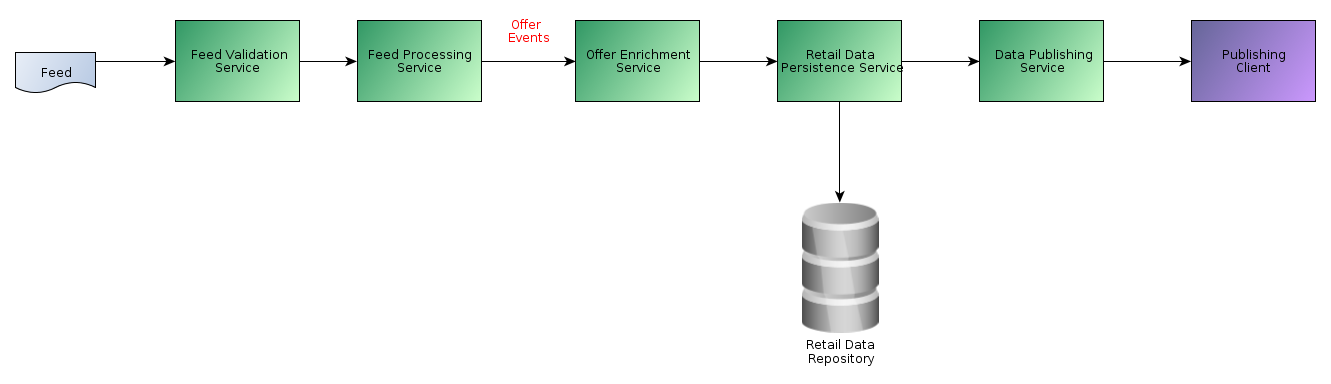
A simplified view of the new inventory platform
As can be seen from the diagram, a feed is ingested by the Feed Validation Service. This validates the feed and transforms it to an internal format. The Feed Processing Service picks it up, performs delta calculations and creates individual “Offer Events” that are streamed to the downstream services where they are persisted and made available to clients.
Each of these services has a defined contract at its API and performs a subset of the overall platform functions. Together the services perform the end to end goal of ingesting a feed and making it available to clients.
We needed to find a way to test not only if a service worked in isolation but also that the services all worked in conjunction with each other. Further, we wanted to experiment with Behaviour Driven Development (BDD). BDD has been around for several years yet it is only recently that the frameworks have begun to get mature enough to use in the development of a new platform.
In order to achieve confidence we came up with the concepts of Blackbox testing and Whitebox testing.
Whitebox testing is individual service or component granular testing. Blackbox testing tests end to end system functionality.
In more detail:
Whitebox tests
- Covers all the scenarios that the service API contract should cover
- The person writing the test cares about the internals of the service, the what, not the how
- Fast set up, execution and tear down
- A large number of tests
- Each test has a lower data set up and tear down overhead, and contains targeted data validation for the scenario under test
Blackbox tests
- Deploy our entire platform freshly onto an integration environment – typically taking the master build of each service.
- Are not concerned about the API contract of services, rather the path data takes through the system
- The person writing the tests only cares about data set up and making sure that the first service in the pipeline is invoked, data is persisted in the correct places and downstream services are notified appropriately
- Slow tests that take longer to run – typically on a scheduled basis
We implemented both the Whitebox and Blackbox tests using BDD. So let’s take a look at example Gherkin files.
Whitebox test Gherkin file
This BDD scenario checks that a German feed can be processed:
Scenario: Accepts feed for Germany Given a feed file with the following contents | titre | id | link | price | sale price | description | | Toms klassische Schuhe | 10 | http://somemerchant.com | 10 | 5 | description | When the system receives an ingestion request Then the output file has the following header row """ unique_id title product_url description original_price unit_price another_header another_header2 """ And maps the following content for the feed: | title | unique_id | product_url | original_price | current_price | | Toms klassische Schuhe | 10 | http://somemerchant.com | 1000 | 500 |
Note that there is neither much data setup, nor data verification. A Whitebox feature file can consist of many scenarios of the same style. So with Whitebox tests we have: small amount of data setup, small amount of data verification, many scenarios per feature.
Blackbox test Gherkin file
Here is the blackbox equivalent of processing a feed – note we don’t care what country it is, that’s left for the Whitebox tests:
Scenario: Feed is processsed by the pipeline Given that the ID generator service on port 6666 allocates ids up to 1970 And all databases are cleanly initialized with no data And the all services are reset flushed And a connection can be made to all databases And the feed information is configured: | merchantId | feedId | feedPreprocessor | protocol | path | feed | encoding | header | delimiter | columns | quotes | country | | 666 | 0 | MyFeedProcessor | http | /feeds/ | feed.csv | UTF-8 | y | , | 5 | n | US | And check that all known services are healthy And the delta repository contains no offers And a file named "feed.csv" with the following contents: | line | | id , MyCategory , Manufacturer , model , product_url , title , price , description | | 227 , 13.050.902 , GE , JEM25DMBB , http://www.somemerchant.com/product/227 , GE Black Spacemaker II Microwave Oven - JEM25DMBB , 155 , microwave! | | 1485 , 11.510.100 , Bose , 17626 , http://www.somemerchant.com/product/1485 , Bose UB-20 Wall/Ceiling Brackets In Black - 17626 , 29.0 , the wall brackets | | 551 , 11.960.000 , Sony , PSL-X250H , http://www.somemerchant.com/product/551 , Sony Turntable - PSL-X250H , 89.00 , amazing | When the Feed Validation Service receives a feed to process: | merchantId | feedId | feedFileLocation | | 666 | 0 | feed.csv | Then within 10 minutes, the delta repository contains: | oid | in_progress | | 1871 | 0 | | 1872 | 0 | | 1873 | 0 | And the "Feed Processing Service" responds with "DONE" for merchantId 666 and feedId 0 And the "Feed Validation Service" responds with "DONE" for merchantId 666 and feedId 0 And within 1 minutes, the Retail Data Repository contains these offers: | oid | merchantId | | 1871 | 666 | | 1872 | 666 | | 1873 | 666 | So for the same function of processing a feed, you can see that the Blackbox tests are more focussed on the end to end, ensuring that known data inputs result in services in the pipeline behave as expected and data is persisted in the appropriate places.
When to run Whitebox and Blackbox tests
We actually run our Whitebox tests as part of our Maven build. Cucumber JVM, which we selected as our BDD framework, makes the integration extremely easy via its Cucumber JUnit runner. Our builds typically take anything from one minute to 4 minutes for a full maven clean install. Note that the four minute build is only one service and it has Hadoop MapReduce based tests using MiniMRCluster which is slow in and of itself. Note: we’ve made some inroads into efficiently BDD testing using Hadoop, but that will be the subject of another blog post.
Our Blackbox tests are run at midnight and take about 40 minutes.
Developing with Blackbox tests
As you can imagine, Whitebox tests are very fast to develop with given they only test one service and are executed as part of the build. Blackbox tests, on the other hand, by their nature require a dedicated environment with all services deployed. We can’t have lots of these as it becomes resource expensive and quite unmanageable. Instead, team members have to communicate when they are using the integration environment, then wait about 2 or 3 minutes while they point the integration environment towards their dev machine. This process is slow because it:
- Sets up all servers to point back to the developer’s machine so that the BDD framework can communicate with the environment when executing the tests
- Deploys the latest version of the services to the integration environment, including any branches of services the developer is working on
As you can imagine, the long running nature of these tests means that the turnaround time is not great. However, we are very specific with the Blackbox tests we create and, now the platform is maturing, our addition of blackbox tests has decreased considerably. Many changes now only require updates to a service’s Whitebox tests.
BDD frameworks
Finally, a quick note on BDD frameworks. Originally we assessed executing BDD tests using Python and Lettuce and Cucumber JVM. We originally thought Python and Lettuce would be faster after our initial assessment so we used that. While using it to develop real functionality, we began to suspect that Python/Lettuce was much slower than Cucumber JVM. Not to mention that Cucumber JVM’s codebase was being regularly committed to and features were being added very quickly. So we converted a suite of tests over to Cucumber JVM to find a roughly 25% reduction in execution time. So we gradually migrated all Whitebox tests for all services to Cucumber JVM and haven’t looked back. Our Blackbox tests are still in Python and Lettuce, which we’ve gotten used to working with. There is a slow initial set up and execution time anyway for the Blackbox tests so the Python/Lettuce decision has far less of an impact. If we were to re-write the Blackbox tests, we’d probably stick with the same approach but use Cucumber JVM.
Future direction
Blackbox and Whitebox testes have worked very well for us, especially the non-coding way writing a BDD failing whitebox test makes us think about what we’re about to implement. We will continue working this way until a better method comes along.
As for the speed of the Blackbox tests, we’re always working on streamlining them. I believe as of writing we’ve just got them down to 20 minutes execution time from 40 minutes.
So how about you? Have you used BDD or the concept of Blackbox and Whitebox tests for a multi-service system? How did it work out?
Note
This is a modified post from the one that originally appeared at http://tech.shopzilla.com/2013/03/blackbox-whitebox-bdd-testing/

Pingback: No more burndown, no more definition of done | Mik Quinlan's Musings on Agile Software Development and Technology